Introduction:
In this article, we are going to learn the core components of the Kubernetes cluster.
A Kubernetes cluster mainly consists master node called the control plane and a set of worker machines, called nodes, that run containerized applications.
The control plane manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers and a cluster usually runs multiple nodes, providing fault tolerance and high availability.
The worker node(s) host the Pods that are the components of the application workload.
Next, We are going to look at the various components in the control plane and worker node of a Kubernetes cluster.
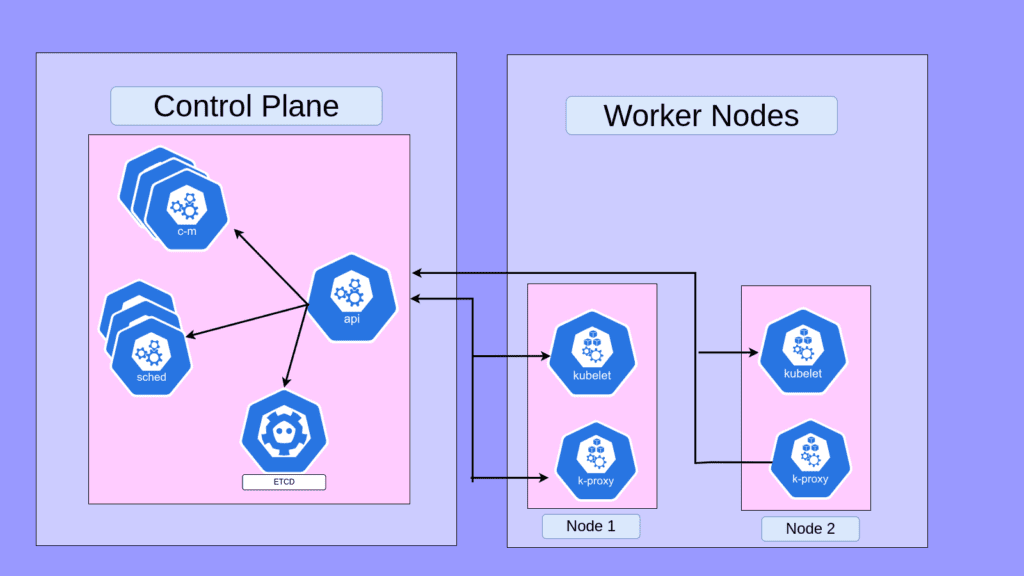
As shown in the above image we can split the kuberenets cluster into2 components. The control plane and the worker nodes.
The control plane’s components make global decisions about the cluster (for example, scheduling), as well as detecting and responding to cluster events (for example, starting up a new pod when a deployment’s replicas the field is unsatisfied).
The control plane consists of 4 main components
The worker nodes are where the pods get placed they maintain the runtime environment for Kubernetes.
The worker node components consist of
Control Plane Components
Control plane components can be run on any machine in the cluster. However, for simplicity, set-up scripts typically start all control plane components on the same machine and do not run user containers on this machine.
kube-apiserver
The API server is a component of the Kubernetes control plane that exposes the Kubernetes API. The API server is the front end of the Kubernetes control plane.
The main implementation of a Kubernetes API server is kube-apiserver. kube-apiserver is designed to scale horizontally—that is, it scales by deploying more instances. You can run several instances of kube-apiserver and balance traffic between those instances.
Kube-apiserver is responsible for authenticating, validating requests, retrieving and Updating data in ETCD key-value store.
It acts as a bridge between the user and the etcd server.
So whenever a user type kubectl get pods commands the API server takes the request from the user and check the etcd server and provide the user with the results.
All commands we run using the kubectl are processed by the kube-apiserver.
etcd
Consistent and highly-available key value store used as Kubernetes’ backing store for all cluster data.
The ETCD Datastore stores information regarding the cluster such as Nodes, PODS, Configs, Secrets, Accounts, Roles, Bindings and Others.
Every information you see when you run the kubectl get the command is from the ETCD Server.
You can find in-depth information about etcd in the official documentation.
Every data of the k8s cluster is stored in etcd server ie if you run kubectl get pods commands the data is retrieved from the etcd server which is processed with the help of apiserver .
etcd listen to port 2379 of the server.
kube-scheduler
Sheduler is a Control plane component that watches for newly created Pods .If a scheduler identifies a new pod created it will immediately assign the node to that pod.
Factors taken into account for scheduling decisions include individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference, and deadlines.
The scheduler continuously monitors the activity of the API server so if an apiserver created a post request to create a new pod. The scheduler identifies that there is a new pod with no nodes assigned so that information is passed to the API-server by the scheduler.
The scheduler only determines which pods go on which node the placement of pods on nodes is done by the kubelet and not by the scheduler
When we assign the CPU and another resource within the pods the scheduler is the one which makes sure that the right pods get deployed to the right node ie Ie we have the right resource-consuming pod the scheduler makes sure that it gets placed in the node which satisfies the resources of the pods.
kube-controller-manager
Control plane component that runs controller processes.
The major responsibility of the controllers is to control the components within the Kubernetes cluster ie if a node goes down it will automatically shift the pods within that node to another node there are various controllers available within Kubernetes.
Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
There are many different types of controllers. Some examples of them are:
- Node controller: Responsible for noticing and responding when nodes go down.
- Job controller: Watches for Job objects that represent one-off tasks, then creates Pods to run those tasks to completion.
- EndpointSlice controller: Populates EndpointSlice objects (to provide a link between Services and Pods).
- ServiceAccount controller: Create default ServiceAccounts for new namespaces.
Node Components
Kubernetes runs your workload by placing containers into Pods to run on Nodes. A node may be a virtual or physical machine, depending on the cluster. Each node is managed by the control plane and contains the services necessary to run Pods.
kubelet
An agent that runs on each node in the cluster. It makes sure that containers are running in a Pod.
The kubelet takes a set of PodSpecs that are provided through various mechanisms and ensures that the containers described in those PodSpecs are running and healthy. The Kubelet doesn’t manage containers which were not created by Kubernetes.
Kubelet along with the container runtime interface deploys the pod and Kubelet updates the status to the api-server.
kube-proxy
kube-proxy is a network proxy that runs on each node in your cluster, implementing part of the Kubernetes Service concept.
kube-proxy maintains network rules on nodes. These network rules allow network communication to your Pods from network sessions inside or outside of your cluster.
kube-proxy uses the operating system packet filtering layer if there is one and it’s available. Otherwise, kube-proxy forwards the traffic itself.
Container runtime
The container runtime is the software that is responsible for running containers.
A container runtime in Kubernetes handles tasks like managing container life cycles, resource allocation, networking, and security to ensure efficient orchestration of containers in a cluster
Kubernetes supports container runtimes such as containers, CRI-O, and any other implementation of the Kubernetes CRI (Container Runtime Interface).
Addons
Addons use Kubernetes resources (DaemonSet, Deployment, etc) to implement cluster features. Because these provide cluster-level features, namespaced resources for addons belong within the kube-system namespace.
Selected add-ons are described below; for an extended list of available add-ons, please see Addons.
DNS
While the other add-ons are not strictly required, all Kubernetes clusters should have cluster DNS, as many examples rely on it.
Cluster DNS is a DNS server, in addition to the other DNS server(s) in your environment, which serves DNS records for Kubernetes services.
Kubernetes simplifies communication within your cluster by generating DNS entries for Services and Pods. This means you can communicate with Services using reliable DNS names instead of dealing with complex IP addresses.
Kubernetes takes care of distributing information about Pods and Services to manage the DNS setup. The Kubelet ensures that running containers can conveniently access Services by their names rather than intricate IP addresses.
When you define Services in your cluster, they’re automatically assigned DNS names, making communication smoother and hassle-free.
Web UI (Dashboard)
Dashboard is a general-purpose, web-based UI for Kubernetes clusters. It allows users to manage and troubleshoot applications running in the cluster, as well as the cluster itself.
Container Resource Monitoring
Container Resource Monitoring records generic time-series metrics about containers in a central database and provides a UI for browsing that data.
Cluster-level Logging
A cluster-level logging mechanism is responsible for saving container logs to a central log store with a search/browsing interface.
Network Plugins
Network plugins are software components that implement the container network interface (CNI) specification. They are responsible for allocating IP addresses to pods and enabling them to communicate with each other within the cluster.
In the next article, we will discuss components like pods, services, deployments, replica sets, daemon sets etc.
Summary:
That’s we have defined the various components within the Kubernetes cluster.
Please note that there are many other components in Kubernetes which will be covered in upcoming tutorials.