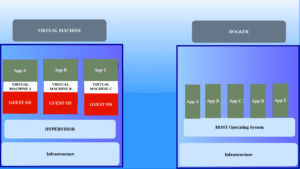
We have already deployed docker containers on a single node machine which is fine for development and testing purposes but for production applications what if that node or machine goes down? All our containers will be inaccessible and cause many issues so we have docker-swarm mode architecture to deploy docker in a production environment. It enables you to deploy and manage a group of containers across multiple hosts, providing load balancing, scaling, and high availability for your applications.

Docker swarm Architecture
A docker swarm consist of mainly manager nodes and worker nodes.
Manager node: It acts as a master node which is responsible for managing the swarm and making global decisions such as scheduling containers, maintaining the desired state of services, and orchestrating communication between the nodes in the swarm. A swarm can have one or more manager nodes, but only one manager node can be the “leader” at any given time. The leader manages the state of the swarm and orchestrates tasks across all nodes.
Worker Node: Worker nodes are responsible for running the application containers. They are managed by the master node and execute the tasks assigned to them by the master. Worker nodes do not participate in swarm management and are typically used for running application workloads.
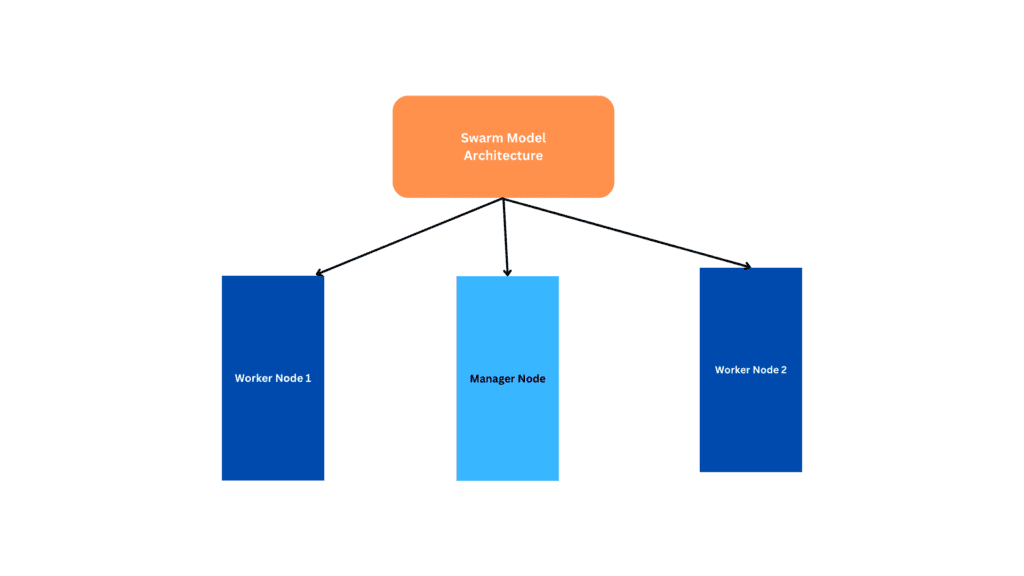
This is the basic architecture of docker-swarm here we have one manager node and 2 worker nodes.
Benefits of docker-swarm
- Scaling: For each service, you can declare the number of tasks you want to run. When you scale up or down, the swarm manager automatically adapts by adding or removing tasks to maintain the desired state.
- Desired state reconciliation: The swarm manager node constantly monitors the cluster state and reconciles any differences between the actual state and you’re expressed the desired state. For example, if you want to run 2 replicas of your task and if one of the nodes goes down docker-swarm will always keep the desired count to 2 by running 2 tasks in the available nodes.
- Multi-host networking: You can specify an overlay network for your services. The swarm manager automatically assigns addresses to the containers on the overlay network when it initializes or updates the application.
- Service discovery: Swarm manager nodes assign each service in the swarm a unique DNS name and load balances running containers. You can query every container running in the swarm through a DNS server embedded in the swarm.
- Load balancing: You can expose the ports for services to an external load balancer. Internally, the swarm lets you specify how to distribute service containers between nodes.
- Rolling updates: At rollout time you can apply service updates to nodes incrementally. The swarm manager lets you control the delay between service deployment to different sets of nodes. If anything goes wrong, you can roll back to a previous version of the service.
What is docker-swarm?
A swarm consists of multiple Docker hosts which run in swarm mode and act as managers (to manage membership and delegation) and workers (which run swarm services).
Any given Docker host can act as both a manager and a worker. When you create a service, you specify its ideal state, including the number of replicas, network and storage resources, ports the service makes available to the public, and more docker works to main that desired state.
We can have either one manager or multiple managers in docker-swarm but only one leader who takes the decisions in the cluster.
What is the RAFT algorithm in docker?
We have learned that we can have multiple manager nodes but only one leader at a time but how does Docker know to select the leader and what happens in the node that is currently in the position of leader went down for that Docker uses the Raft algorithm in these cases.
Raft Algorithm uses random timers for initiating requests. Suppose we have 3 managers docker sends random requests across these 3 managers the first one to complete the timer sends out a request to another manager requesting permission to be the leader. This is how the leader is been selected if we have multiple managers nodes. The leader node will continuously send requests to other master nodes to inform them that it is continuing its role as the leader.
If the other manager nodes don’t get a request from the leader node for a particular period of time they do the reelection process within themselves and select the new leader node.
Also, every manager node stores information about the RAFT database and they make sure that every database is in sync to avoid inconsistency. When a new node joins the cluster, it will communicate with the existing nodes using the RAFT algorithm to synchronize the cluster state.
You can refer to more about the RAFT process in the below link.
https://docs.docker.com/engine/swarm/raft/
Creating a Swarm Cluster
For creating a swarm cluster I have provisioned 2 ec2 Ubuntu instances one will act as the manager node and the other will be the worker node and installed docker on them. You can follow our below articles to install docker in Ubuntu
how-to-install-docker-in-ubuntu.
The first thing you need to do is to initialize the cluster using the docker swarm init command on the master node

You will get a response similar to the above-shown image. Now copy the docker swarm join command and run the same in the worker node.

After running the docker swarm join command on the worker node you will be able to see the output the node has joined the swarm as a worker as in the above shown image.
If you want to leave the cluster use the docker swarm leave command on your worker node.
Now your worker has joined the swarm cluster to confirm it run the docker node ls command on the master node and you will be able to see both the manager node and the worker node.

The output itself shows the leader node and the * symbol indicated the current system you are in. Now our nodes are joined to our cluster we can start working on our cluster.
We Will learn more about the docker-swarm and its features in the coming articles.
Summary: In this article, we have learned the basics of docker-swarm and how to create a swarm cluster
Docker swarm tutorials: